Diffusion_model 应用(Huggingface)
Diffusion_model
1. DEMO引入
从头开始训练一个扩散模型 关于🤗 Diffusers核心API的介绍,主要包括三个主要组件:
管道 (Pipelines):这是高级类,旨在以用户友好的方式快速生成来自流行的经过训练的Diffusion模型的样本。管道的作用是让用户可以轻松地使用这些模型生成数据样本。
模型 (Models):这是用于训练新的Diffusion模型的流行架构,例如UNet。在这里,模型指的是用于创建Diffusion模型的结构和参数。
调度程序 (Schedulers):这是用于在推断期间从噪音生成图像以及生成用于训练的有噪图像的各种技术。调度程序的作用是管理如何使用噪音生成图像,无论是在推断时生成清晰图像,还是在训练中生成有噪图像。
对于终端用户来说,管道是非常有用的,但如果你正在学习这门课程,我们假定你想要深入了解它的内部工作原理。因此,在本笔记本的其余部分,我们将构建自己的管道,能够生成小蝴蝶图片。最终结果是一个能够生成小蝴蝶图片的自定义管道。
从加载一个蝴蝶图像集库 来使用扩散模型生成图片
1 | import numpy as np |
创建函数方法 便于后续使用
1 | from diffusers import DDPMPipeline |

DDPMPipeline类加载了一个预训练的 Deep Diffusion Probabilistic Model(DDPM)流水线,该模型用于生成蝴蝶图像。然后,它使用该流水线生成了8张蝴蝶图像,并通过make_grid` 函数将这些图像以横向排列的方式展示出来
训练一个扩散模型的步骤是这样的:从训练数据中加载一些图像。 添加不同程度的噪音。 将这些带噪声的输入馈送到模型中。 评估模型在去噪这些输入方面的表现。 利用这些信息来更新模型权重,然后重复上述步骤。
1.2 数据处理
1 | import torchvision |
通过对数据集进行数据增强,然后转化为PIL格式 便于后续处理
1.3 定义调度程序
我们希望的是将这些输入图像添加噪音,然后将这些带噪声的图像馈送给模型。推断期间,使用模型预测逐步去除噪音
噪音调度程序确定在不同时间步骤添加多少噪音。以下是如何使用默认设置创建调度程序,用于’DDPM’的训练和采样(基于论文”Denoising Diffusion Probabilistic Models”):
1 | from diffusers import DDPMScheduler |
这段代码提供了两个不同的选项,您可以尝试不同的设置来观察noise_scheduler中α值的变化。以下是这两个选项的解释:
One with too little noise added:
这个选项使用DDPMScheduler创建了一个噪音调度程序。 num_train_timesteps指定了训练的时间步数。 beta_start和beta_end是控制噪音添加的参数。在这个选项中,它们分别设置为0.001和0.004,这可能会导致噪音添加得太少,从而影响训练效果
The ‘cosine’ schedule, which may be better for small image sizes:
这个选项也使用DDPMScheduler创建了一个噪音调度程序。 num_train_timesteps指定了训练的时间步数。 beta_schedule参数设置为’squaredcos_cap_v2’,这是一种不同于默认设置的β调度方案,可能对小图像尺寸更合适。 您可以尝试替换原始的noise_scheduler设置为其中一个选项,然后运行相同的绘图代码,以查看不同设置下α值的变化情况。这可以帮助您理解噪音调度对模型训练的影响
现在让我们对图片生成噪音noise
1 | timesteps = torch.linspace(0, 999, 8).long().to(device) |

创建一个名为timesteps的张量,其中包含8个时间步,表示训练中的时间步。
使用torch.randn_like生成一个与xb(原始图像批次)相同大小的噪音张量。
使用noise_scheduler.add_noise方法,将噪音添加到原始图像批次xb上,同时考虑时间步timesteps。
打印输出添加噪音后的图像数据的形状。
使用show_images函数将添加了噪音的图像批次转换为PIL图像。
使用resize方法将PIL图像的尺寸调整为(8 * 64, 64)像素,使用最近邻插值(Image.NEAREST)。
这段代码的目的是演示如何使用噪音调度程序在训练中向原始图像添加噪音,然后显示添加噪音后的图像。这有助于理解噪音如何逐步应用到图像上以进行训练。
1.4 定义Model
大部分扩散模型使用的都是Unet的变形,这里也是使用的unet的变形
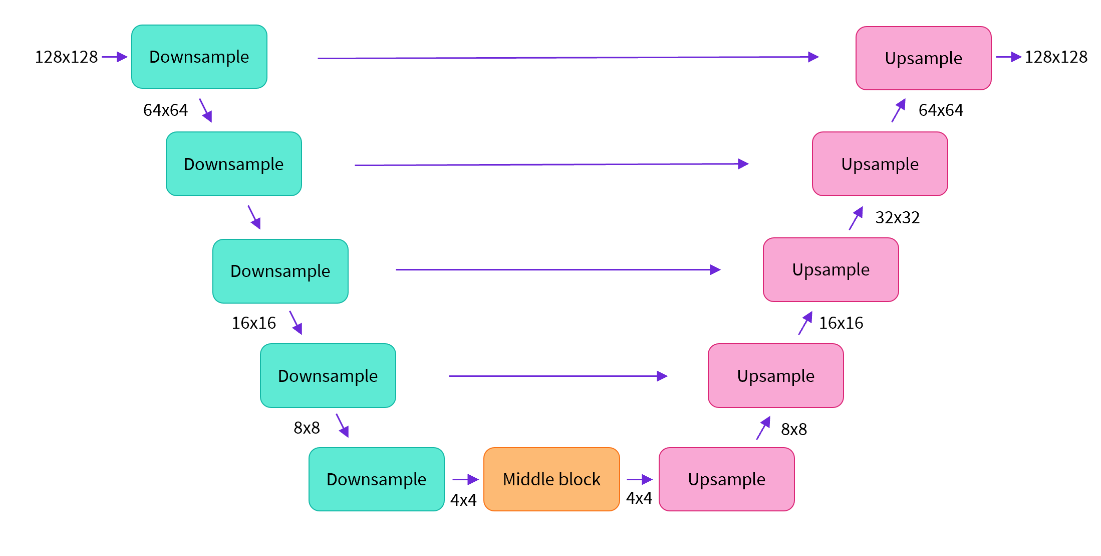
简而言之,这个模型的工作原理如下:
模型将输入图像通过若干个ResNet层块进行处理,每个块都将图像大小减半。 然后,经过相同数量的块来进行上采样,将图像大小恢复。 存在跳跃连接,将下采样路径中的特征连接到上采样路径中相应的层。 这个模型的一个关键特点是它预测与输入相同大小的图像,这正是我们在这里需要的。
Diffusers为我们提供了一个方便的UNet2DModel类,可以在PyTorch中创建所需的架构。
让我们为所需的图像大小创建一个U-net。请注意,down_block_types对应于下采样块(上图中的绿色块),而up_block_types对应于上采样块(上图中的红色块)。
1 | from diffusers import UNet2DModel |
sample_size:模型的输入和输出图像的目标分辨率。在这里,它被设置为image_size,这是之前定义的图像分辨率,通常是32x32像素。in_channels:输入图像的通道数。通常,RGB图像有3个通道(红、绿、蓝),因此这里设置为3。out_channels:输出图像的通道数。同样地,输出图像也有3个通道,与输入通道数相同。layers_per_block:每个UNet块中使用的ResNet层数。UNet块是UNet架构的一部分,用于特征提取和上/下采样。block_out_channels:每个UNet块中的输出通道数。这个参数指定了不同层次的特征图的通道数,通常随着网络深度的增加而增加。在这里,有4个块,每个块的输出通道数依次为(64, 128, 128, 256)。down_block_types:下采样块的类型。在UNet中,有一些块用于下采样操作,以便提取特征。在这里,有4个块,其中一些是具有自注意机制的块(”AttnDownBlock2D”),而其他是常规的ResNet下采样块(”DownBlock2D”)。up_block_types:上采样块的类型。与下采样块类似,上采样块用于将特征图向上采样,以便进行生成操作。在这里,同样有4个块,包括一些具有自注意机制的块和常规的ResNet上采样块。这个模型的设计允许进行图像生成或其他图像处理任务。它结合了U-Net的结构和ResNet的块,还包括自注意机制,以提高对图像内容的建模能力。模型可以根据任务的需要进行训练,并生成或处理图像数据。
下面将会描述 如何训练这个模型
1.5 创建训练循环
是时候开始训练了!下面是一个典型的PyTorch优化循环,其中我们逐批处理数据,并使用一个优化器在每一步中更新模型的参数。在本例中,我们使用了学习率为0.0004的AdamW优化器。
对于每批数据,我们执行以下操作:
随机采样一些时间步骤。 根据时间步骤对数据进行加噪处理。 将加噪数据输入到模型中。 使用均方误差作为我们的损失函数,将模型的预测与目标数据(在这种情况下是噪声)进行比较。 通过 loss.backward() 和 optimizer.step() 更新模型参数。 在这个过程中,我们还记录了随时间变化的损失值,以便稍后绘制图表。
1 | # Set the noise scheduler |
通过训练后的损失率 制作图表
1 | fig, axs = plt.subplots(1, 2, figsize=(12, 4)) |
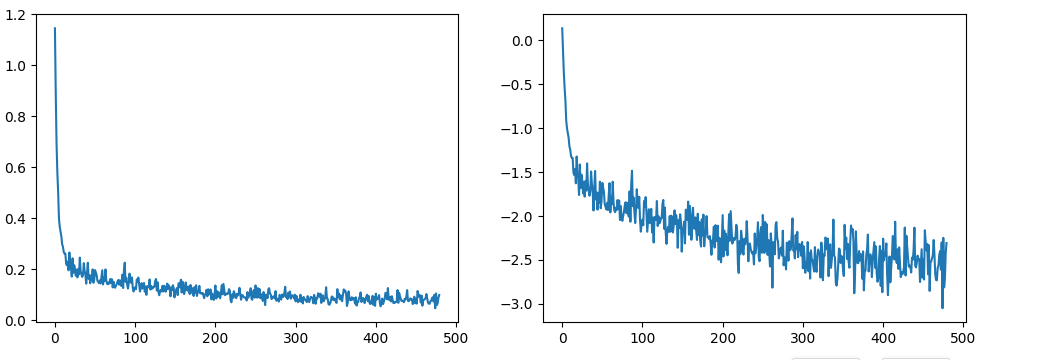
第一张图代表着随着训练的进行,损失值不断地下降,第二张图通过损失值的对数 放大了损失值的细节 可以看出损失的小幅变化
1.6 生成图片
How do we get images with this model?
1 | from diffusers import DDPMPipeline |
导入模型 来生成图片 或者可以自己训练一个模型来生成并推送到github上
